-
展开式与矩阵形式的方程及模型设定
-
经典假设——5条
及E(μi)=0 , E(μ′μ)=σ2I , μ∼N(0,σ2I)
-
OLS估计
-
极大似然估计
-
MM矩估计
β=(X′X)−1X′Y ,(离差形式:β=(x′x)−1x′Y)
-
满足经典假设的估计量性质:
线性性
无偏性
有效性 cov(β)=σ2(X′X)−1
-
σ2=n−k−1e′e
-
拟合优度:
R2=TSSESS and adj−R2=1−(1−R2)∗n−k−1n−1
AIC(赤池信息准则)=lnne′e+n2(k+1)
AC(施瓦茨准测)= lnne′e+nklnn
-
回归方程显著——F统计量
F=RSS/n−k−1ESS/k=1−R2R2×kn−k−1∼F(k,n−k−1)
-
受约束回归/解释变量数量是否变动:
构造F统计量
F=RSSU/(n−k−1)RSSR−RSSU/(kU−kR)∼F(kU−kR,n−k−1)
-
变量显著性检验——t统计量
t=se(β)β−β∼t(n−2)
-
参数置信区间:
(β−t2α×se(β),β+t2α×se(β))
se(β)=σCii
-
E(Y0)的置信区间
Y0−t2α×se(Y0),Y0+t2α×se(Y0)
se(Y0)=σX0(X′X)−1X0′
-
Y0的置信区间
e0=Y0−Y0
[Y0−t2α×se(e0),Y0+t2α×se(e0)]
se(e0)=σ1+X0(X′X)−1X0′
-
c1xi1+c2xi2+...+ckxik=0 , 其中 ci 不全为0——完全共线性
-
c1xi1+c2xi2+...+ckxik+vi=0, 其中ci不全为0, vi为随机误差项——近似共线性/交互相关
-
Rank(X)<k+1——完全共线性
-
产生原因:
解释变量之间有相同变化趋势
模型设定问题
数据资料限制
-
多重共线性后果
OLS估计量不存在 , 因为(X′X)−1不存在
OLS估计量非有效, Cov(β)=σ2(X′X)−1增大
r2=∑x1i∑x2i∑x1ix2i
r2=0时, 完全不共线, var(β)=∑x12σ2
0<r2<1, 近似共线, var(β)=∑x12σ2×1−r21>∑x12σ2, 其中1−r21为方差膨胀因子;
r2=1, 完全贡献, var(β)=∞
估计量不具有经济含义
估计量反映的时解释变量对被解释变量的共同影响
变量显著性检验失去意义
存在多重共线性时, 估计参数的标准差和方差变大, 使t统计量变小
模型预测功能失效
预测的区间变大
-
检验多重共线性问题
检验是否存在多重共线性以及存在共线性的变量是哪些
是否存在:变量间的相关系数r2;或者看OLS估计中R2及F统计量较大, 但t统计量较小/不显著
判定系数法:对每一解释变量以其他变量作为解释变量作辅助回归, Xji=α1X1i+α2X2i+...+αkXki的判定系数Rj2, 给定显著水平下, 计算F=(1−Rj2)/(n−k)Rj2/(k−1)∼F(k−1,n−k)
排除变量法:比较排除一个解释变量与加入改解释变量的R2
逐步回归法:逐步加入解释变量, 观察R2变化是否显著
-
克服多重共线性:
排除引起多重共线性的变量——逐步回归法
减小参数估计量的方差——岭回归法
以引入偏误为代价, 减小参数估计量的方差
β=(X′X+D)−1X′Y
-
var(μi)=σi2, 选取不同的样本, 随机误差项的方差不再是常数, 则认为存在异方差;
同方差:σi2=常数=f(Xi) and 异方差:σi2=f(Xi)
由σi2=f(Xi) 中σ与X的关系, 可得单调递增型/单调递减型/复杂型
-
异方差的后果:
参数估计量非有效:
OLS估计量仍然无偏, 但不具有有效性, 由于E(μ′μ)=σ2I
大样本下具有一致性, 但不具有渐进有效性
变量显著性检验失去意义:
t统计量的构造建立在σ2不变从而正确估计se(β)
模型预测失效:
预测值的置信区间使用到了参数的标准差估计量se(β)
-
检验异方差:
检验随机误差项与解释变量之间的相关性及相关“形式”
varμi=E(μi2)≈ei2
ei=Yi−(Yi)ols
图示法:
X-Y的散点图——是否存在明显的散点扩大、缩小或复杂变化
X-e2的散点图——平行于X轴/正相关/负相关/曲线
布罗施-帕甘(B-P)检验:
检验随机项的方差是否与解释变量相关
e2=δ0+δ1Xi1+δ2Xi2+...+δkXik+εi
检验联合假设H0:δ0=δ1=δ2=...=δk=0, 同方差的原假设
有R2构造F统计量或拉格朗日乘数(LM)
F=(1−R2)/(n−k−1)R2/k∼F(k,n−k−1)
LM=n⋅R2∼X2(K)
怀特(White)检验:
以二元为例
Yi=β0+β1Xi1+β2Xi2+μi
计算 ei2=Yi−Yi
辅助回归: ei2=α0+α1Xi1+α2Xi2+α3Xi12+α4Xi22+α5Xi1Xi2+εi
同方差假定下: nR2∼X2(h) 渐进服从分布, 存在异方差时, 表明随机项的平方与解释变量的某种组合存在相关性
-
异方差的修正:
加权最小二乘法
对原模型进行加权, 使其不存在异方差, 之后使用OLS估计
∑Wiei2:对较小的ei2赋予较大的权数, 较大的ei2赋予较大的权数
var(μi)=E(μi2)=f(Xij)σ2
f(Xij)1Yi=f(Xij)1β0+f(Xij)1β1Xi1+f(Xij)1β2Xi2+...+f(Xij)1βkXik+f(Xij)1μi
⇒var(μi∗)=f(Xij)1E(μi2)=σ2
⇒β=(X∗′X∗)−1X∗′Y∗
方差μ与X的函数关系时估计, 成为可行的广义最小二乘法;
异方差稳健标准误法
异方差只影响估计量的标准差和方差, 不影响无偏性与一致性, 修正相应方差即可;
得到的并非有效估计量, 但可以得到OLS正确方差估计, 使统计检验及预测区间更加可靠;
-
内生解释变量:
内生解释变量与随机误差项同期相关, 异期不相关;
内生解释变量与随机干扰项同期相关;
-
内生解释变量产生原因:
被解释变量与解释变量双向因果——联立因果关系
使用联立方程模型来描述互为因果关系;
联立方程模型的每个方程为结构方程;
遗漏了重要解释变量, 且所遗漏的解释变量与其他解释变量同期相关
解释变量存在测量误差
-
内生解释变量问题的后果:
不同性质的内生解释变量会产生不同的后果
对截距项和斜率项同时存在影响, 可能高估也可能低估;
参数估计量有偏;大样本下, 不同期相关是一致估计量, 同期相关是非一致估计量;
-
工具变量法:
满足条件:与内生解释变量相关性;与随机误差项不相关-外生性;与其他解释变量不高度相关;
利用MM矩估计:矩条件——正规方程组;
一元:β1=∑zixi∑ziyi
多元:β=(Z′X)−1Z′Y
大样本下为一致估计量;小样本下仍然是有偏的;
-
三种估计方法:
IV:
第一步是OLS法, 进行X关于工具变量Z的回归: Xi=α0+α1Zi
由第一步得到的Xi 为解释变量再次进行OLS回归:Yi=β0+β1Xi
得到 β1=∑zixi∑ziyi
2SLS: 一个内生解释变量有多个工具变量
Yi=β0+β1Xi+β2Zi+μi , (Z外生变量, X为内生变量)
第一阶段, 内生解释变量X关于工具变量Z1 和 Z2及Z的OLS回归(即关于含IV在内的所有外生变量回归), 得到X的拟合值:
Xi=α0+α1Zi1+α2Zi2+α3Zi
第二阶段, 以第一阶段的Xi替代原模型的Xi进行回归:
Yi=β0+β1Xi+β2Zi+μi
得到一致估计量;
GMM广义矩估计:一个内生解释变量有多个工具变量
识别问题:1个内生解释变量对应一个IV为恰好识别;否则为过度识别, 过度识别可使用2SLS方法;
-
内生性检验:
比较工具变量估计与直接OLS估计的结果是否有显著差异, 若差异显著, 为内生变量;
豪斯曼(Hausman)检验:
第一步:将内生变量X关于Z1 and Z2作OLS估计, 得到残差V:
Xi=α0+α1Zi1+α2Zi2+vi
第二步:将残差加入原模型, 再做OLS估计:
Yi=β0+β1Xi+β2Zi1+δVi+εi
如果V的参数显著为0, 表明随机误差项v与Y同期无关, 进而与原模型随机误差项μ同期无关, 外生变量Z1,Z2显然与μ同期无关, 则X与μ同期无关;
不拒绝δ=0的假设, 则可判断X是同期外生变量, 否则X为同期内生变量;
若有多个内生变量, 则逐个与外生变量做OLS, 并将得到的残差都引入原模型;
-
过度识别约束检验:
内生解释变量对应的IV多于1个时, 要对其外生性进行检验:
对原模型进行2SLS
记录的残差项关于IV及所有外生变量作ols
对工具变量前的系数做联合F检验
-
随机项之间存在相关性:
cov(μi,μj)=E(μi,μj)=0
var(μ)=E(μμ′)=σ2Ω=σ2I
-
仅存在cov(μt,μt+1)=0时, 为一阶列相关或自相关;
μt+1=ρμt+εt
ρ为自协方差系数或一阶自相关系数;
-
白噪声:
εt 满足:
E(εt)=0 , var(εt)=σ2 , cov(εi,εi−s)=0
-
产生序列相关的原因:
经济变量固有的惯性——时间序列上的前后关联;
模型设定偏误——遗漏重要的解释变量或函数形式设定偏误;
数据的“编造”——新生成的数据与原始数据存在相关性;
-
序列相关的后果:
参数估计量非有效 E(μ′μ)=σ2I, 参数的有效性证明建立在同方差及相互独立的基础上;
大样本情形下, 参数估计量是一致的, 但不具有渐进有效性;
变量显著性检验失去意义:显著性检验同样建立在随机误差项同方差及相互独立的基础上, 存在序列相关时, 参数的方差估计存在偏误, t统计量存在偏误;
模型预测失效:异方差, 参数估计量方差的估计量存在偏误, 预测区间精度降低;
-
序列相关检验:
首先OLS估计, 得到随机误差项的近似估计et=Yt−Yt, 分析随机误差项之间的相关性;
图示法——et−t的散点图
回归检验法:
以et为被解释变量, et−1 , et−2 , et2等作为解释变量建立回归方程;
利于确定序列相关的形式, 适用于任何类型的序列相关问题检验;
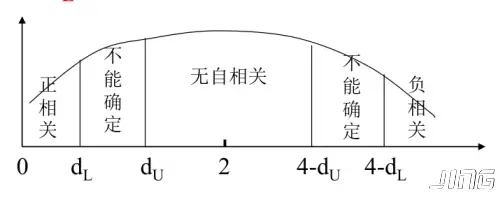
杜宾-瓦森D.W.检验法:检验序列自相关;
假定条件:
解释变量X随机
随机误差项μt一阶自相关, μt=ρμt−1+εt
回归模型中不含有被解释变量滞后项
回归具有截距项
构造 D.W.统计量 =∑t=1net2∑t=2n(et−et−1)
临界值的下限dL与上限dU, 只与样本容量n及解释变量k有关, 与解释变量X取值无关;
给定显著水平α, 由n及k查询DW分布表;
比较、判断:
0<DW<dL, 存在正相关
dL<DW<dU, 不能确定
dU<DW<4−dU,无自相关
4−du<DW<4−dL, 不能确定
4−dL<DW<4, 存在负相关

当n较大时, D.W.≈2(1−ρ)
一阶自回归中, 估计 ρ=∑t=2net2∑t=2netet−1
完全一阶正相关, ρ=1, D.W.≈0
完全一阶负相关, ρ=−1, D.W.≈4
完全一阶不相关, ρ=0, D.W.≈2
拉格朗日乘数检验: 适合高阶序列相关及模型中包含被解释变量滞后项的情形(BG检验)
Yt=β0+β1Xt1+β2Xt2+...+βkXtk+μt
怀疑μt存在p阶序列相关:
μt=ρ1μt−1+ρ2μt−2+...+ρpμt−p+εt
BG检验:构造受约束回归方程:
Yt=β0+β1Xt1+β2Xt2+...+βkXtk+ρ1μt−1+ρ2μt−2+...+ρpμt−p+εt
约束条件H0:ρ1=ρ2=...=ρp=0
计算残差序列et
构造辅助回归:
et=β0+β1Xt1+β2Xt2+...+βkXtk+ρ1et−1+ρ2et−2+...+ρpet−p+εt
计算辅助回归的R2
约束为真时, 大样本下LM=n⋅R2∼χ2(p)
给定显著水平α, 比较χα2(p)与LM值, 可由1阶逐步向高阶进行检验
-
序列相关补救:
广义最小二乘法(GLS):
Cov(μμ′)=E(μμ′)=σ2Ω
存在可逆矩阵D使Ω=D′D
变换原模型:D−1Y=D−1Xβ+D−1μ, 使模型同方差且随机误差项相互独立
E(μ∗μ∗′)=σ2I
OLS估计:β∗=(X′Ω−1X)−1X′Ω−1Y
广义差分法:将模型变化为不存在序列相关的差分模型, 再OLS估计:
Yt=β0+β1Xt1+β2Xt2+...+βkXtk+μt
怀疑μt存在p阶序列相关:
μt=ρ1μt−1+ρ2μt−2+...+ρpμt−p+εt
差分变化: Yt−ρ1Yt−1−...−ρpYt−p=β0(1−ρ1−...ρk)+β1(Xt,1−ρ1Xt−1,1−...−ρpXt−p,1)+...+βk(Xt,k−ρ1Xt−1,k−...−ρpXt−p,k)
OLS估计差分模型, 得到参数无偏、有效估计量;
-
随机误差项相关系数估计:
科克伦-奥科特迭代法:
Yi=β0+β1Xi+μi作ols估计得到et
ols估计et=ρ1et−1+ρ2et−2+...+ρpet−p+εt, 得到相关系数第一次估计值
将估计值代入广义差分模型, 进行OLS估计, 得到β估计值
由参数估计值计算Yi作为被解释变量, 再次作OLS估计, 得到新的et, 对残差相关系数作二次估计
一般迭代两次就可以得到较为满意的结果, 科克伦-奥科特两步法;
-
FGLS可行的广义最小二乘法:可以求得Ω或随机项的相关系数;
-
序列相关稳健标准误法:
Newey-West标准误, 可以得到序列相关的正确标准误, 得到OLS正确方差估计;
-
虚假序列相关:
由模型设定偏误引起, 可以通过调整模型避免;
-
时间序列平稳可以替代随机抽样假定, 随机误差项仍满足正态分布的假定;
-
避免虚假回归(为回归):
时间序列不平稳时, 产生伪回归现象;
Yt=Y0+∑e1t
Xt=X0+∑e2t
e1t 与 e2t 弱相关关系, 由此产生的两个随机游走时间序列应同样没有相关关系, 但回归测试后发现存在
显著相关关系;
对两个序列做差分, 可能会使序列变得平稳;
回归之前需要先检验, 如果检验不平稳, 需要处理为平稳序列;
-
平稳性:
过去的变化及波动应该处于合理的区间, 以保障预测存在合理性;
严平稳性-yt
{y1,y2,...,yt} 的联合概率分布与{y1+k,y2+k,...,yt+k}的联合概率分布相同
弱平稳性(常用)
yt的均值、方差不随时间变化, 协方差仅与观测值之间的距离而与所处的时间点无关
E(yt)=μ
var(yt)=E(yt−μ)2=σ2
cov(yt,yt+k)=γk=E[(yt−μ)(yt+k−μ)]=E[(yt+m−μ)(yt+m+k−μ)]
非平稳时, 期望值是依赖时间变化的
-
常见非平稳随机过程 (stochastic processes)
无漂浮随机游走 (Random Walk without Drift)
Yt=Yt−1+et
其中et是均值为 0, 方差为σ2的白噪声 (shock)
Yt=Y0+∑et
then:
E(Yt)=E(Y0+∑et)=Y0
var(Yt)=tσ2
随时间的增加, 方差会增大;
有漂浮随机游走 (Random Walk with Drift)
yt=δ+yt−1+et (漂浮项δ , 使时间序列有时间趋势——非平稳)
Xt=ϕXt−1+μt
当−1<ϕ<1时, 该随机过程平稳
-
平稳性检验:
避免伪回归现象;
判断方法:
散点图判断平稳性(看均值或者离散程度);
平稳时间序列围绕一个值上下波动;
样本自相关函数判断平稳性:
总体自相关函数(autocorrelation function, ACF)
ρk=γ0γk=var(yt)cov(yt,yt+k)
样本 ACF
ρk=γ0γk=∑(yt−y)2∑(yt−y)(yt+k−y)
白噪声的 ACF=0 ,是没有信息可以提取的平稳序列;
非平稳序列的 ACF 衰减比较慢;
White Noise (i.i.d- independent and identically distributed)
Gaussian white noise: 服从0均值, σ2方差的正态分布;
All the ACFS are zeros;
Test: Q统计量 H0:ρ1=ρ2=...=ρk=0
Portmanteau (Q)Statistic: Q∗=T∑l=1mρl2∼χ2(m)
非平稳时间序列ACF特征:当k增大时, 衰减比较慢;
平稳时间序列ACF特征:当k增大时, 衰减比较快;
单位根 (unit root)
yt=ρyt−1+et
yt−ρyt−1=et
yt−ρLyt=et
(1−ρL)yt=et
⇒1−ρz=0
z=ρ1>1 为平稳序列
ρ=1 则该过程为无漂移随机游走随机过程, 该过程非平稳, 称该过程具有单位根;可以做一次差分使序列变得平稳;(一个单位根)
∣ρ∣<1 时, 可以证明yt 是平稳的;
若yt=2yt−1−yt−2+et 可得z1=1,z2=1 存在两个单位根, 做两次差分, 变得平稳;
Dickey-Fuller 单位根检验
适用于一阶自相关
yt=ρyt−1+et
两边同时减去yt−1
then: yt−yt−1=(ρ−1)yt−1+et 即 Δyt=δyt−1+et
检验原假设:H0:δ=0 (非平稳)
Augmented Dickey-Fuller (ADF) test
适用于高阶序列相关或包含明显时间趋势项的情形
Δyt=δyt−1+∑j=1LλjΔyt−j+et
Δyt=α+δyt−1+∑j=1LλjΔyt−j+et
Δyt=α+βt+δyt−1+∑j=1LλjΔyt−j+et
带有时间趋势项的非平稳序列, 可以通过去除趋势项使其变的平稳;
针对H0:δ=0 (非平稳)
模型3-2-1的顺序进行检验
-
单整序列:
一阶差分可以变平稳 I(1)
-
变量之间存在长期稳定的关系, 即变量之间协整, 可以使用经典回归模型方法建立回归模型;
-
经济变量之间长期均衡:Yt=α0+α1Xt+μt, 可以确定Y的均衡值
存在长期均衡关系时, Y对其均衡点的偏离本质上是“临时性”的
长期均衡下, μt=Yt−α0−α1Xt 应该是0均值的I(0), 平稳序列
-
协整:
两个单整序列, 单整阶数相同时才可能协整;
(d,d)阶协整——表明变量之间存在长期稳定的比例关系, 可以建立回归模型;Yt,Xt∼CI(1,1)
-
协整检验:EG检验
OLS估计Yt=α0+α1Xt+μt, 得到残差et
检验残差序列是否I(0)——ADF检验
-
多变量协整检验
协整变量间可能存在多种稳定的线性组合
仍是OLS估计后, 估计误差(加总)是否为I(0)序列
设置一个变量为被解释变量, 其他为解释变量, 检验残差序列是否平稳, 若不平稳则更改被解释变量直到平稳;
-
高阶单整变量的协整检验
没有成熟的临界值分布表
-
只能有协整检验均衡:
协整的随机误差是平稳的, 均衡方程的随机误差是白噪声
-
误差修正:
非平稳时间序列, 直接差分后建立回归模型ΔYt=α1ΔXt+vt
vt可能序列相关
采用差分形式估计, 关于变量水平值的重要信息将被忽略, 只表达了X与Y之间的短期关系, 没有揭示长期关系;
Y在t期的变化, 不仅取决于X本身的变化, 还取决于X与Y在t-1期末的状态;
-
误差修正模型:(ECM模型-DHSY模型)
Yt=α0+α1Xt+μt
加入一阶滞后项:Yt=β0+β1Xt+β2Xt−1+β3Yt−1+μt
变量可能非平稳, 进行差分变换:ΔYt=β1ΔXt−(1−β3)(Yt−1−1−β3β0−1−β3β1+β2)+μt
ΔYt=β1ΔXt−λ(Yt−1−α0−α1Xt−1)+μt
Y的变化取决于X的变化及前一期的非均衡程度:ΔYt=β1ΔXt−λecmt−1+μt
长期均衡解:α0+α1Xt , α1为Y关于X的长期弹性
短期非均衡模型:Yt=β0+β1Xt+β2Xt−1+β3Yt−1+μt, β1为短期弹性
-
误差修正:引入更多滞后项
二阶误差:增加ΔYt−1及ΔXt−1项
-
误差修正:多变量
增加另一个变量的短期弹性
-
建立误差修正模型:
优点:Granger表述定理
消除变量可能存在的趋势因素
消除多重共线性
保留变量水平值信息
可以使用经典回归方法估计, 及F/t检验
协整变量, 建立短期模型;
EG两步法:OLS协整回归, 将OLS估计的非均衡误差项的滞后一期加入回归, 估计短期弹性;
ΔYt=lagged(ΔYt,ΔXt)−λecmt−1+μt
直接估计法:对ΔYt=λα0+βΔXt−λYt−1+λα1Xt−1+μt作OLS估计